

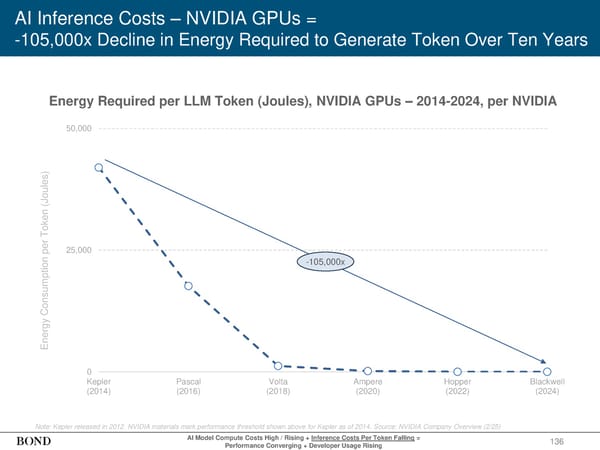
136 AI Inference Costs – NVIDIA GPUs = -105,000x Decline in Energy Required to Generate Token Over Ten Years Energy Consumption per Token (Joules) AI Model Compute Costs High / Rising + Inference Costs Per Token Falling = Performance Converging + Developer Usage Rising 0 25,000 50,000 Kepler (2014) Pascal (2016) Volta (2018) Ampere (2020) Hopper (2022) Blackwell (2024) -105,000x Note: Kepler released in 2012. NVIDIA materials mark performance threshold shown above for Kepler as of 2014. Source: NVIDIA Company Overview (2/25) Energy Required per LLM Token (Joules), NVIDIA GPUs – 2014-2024, per NVIDIA
 2025 | Trends in Artificial Intelligence Page 136 Page 138
2025 | Trends in Artificial Intelligence Page 136 Page 138