

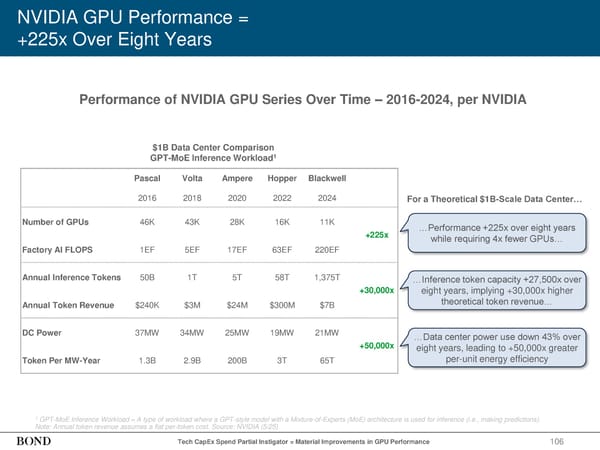
NVIDIA GPU Performance = +225x Over Eight Years 106 1 GPT-MoE Inference Workload = A type of workload where a GPT-style model with a Mixture-of-Experts (MoE) architecture is used for inference (i.e., making predictions). Note: Annual token revenue assumes a flat per-token cost. Source: NVIDIA (5/25) Performance of NVIDIA GPU Series Over Time – 2016-2024, per NVIDIA Tech CapEx Spend Partial Instigator = Material Improvements in GPU Performance Pascal Volta Ampere Hopper Blackwell 2016 2018 2020 2022 2024 Number of GPUs 46K 43K 28K 16K 11K +225x Factory AI FLOPS 1EF 5EF 17EF 63EF 220EF Annual Inference Tokens 50B 1T 5T 58T 1,375T +30,000x Annual Token Revenue $240K $3M $24M $300M $7B DC Power 37MW 34MW 25MW 19MW 21MW +50,000x Token Per MW-Year 1.3B 2.9B 200B 3T 65T …Performance +225x over eight years while requiring 4x fewer GPUs… $1B Data Center Comparison GPT-MoE Inference Workload1 …Inference token capacity +27,500x over eight years, implying +30,000x higher theoretical token revenue… …Data center power use down 43% over eight years, leading to +50,000x greater per-unit energy efficiency For a Theoretical $1B-Scale Data Center…
 2025 | Trends in Artificial Intelligence Page 106 Page 108
2025 | Trends in Artificial Intelligence Page 106 Page 108